Understanding Git — Data Model

Since its birth in 2005 git has become massively popular especially in the open-source world but many of us use it on our job posts also. It is a great VCS tool and has many advantages, but being easy to learn is just not one of them. Which can make us frustrated since we use it so often. In my opinion, the only way to get comfortable with using git and maybe even start loving it is to learn about how it works internally. The reason why I think so was perfectly summarized in a statement given by Edward Thomson in his lecture Deep Dive Into Git :
The Git commands are just a leaky abstraction over the data storage.
This is why no matter how many git commands or tips ‘n tricks you memorize or store in your git cheatsheet, without understanding of how git works under the hood you will remain confused with the strange ways of git because that git internals will every once in awhile leak through the abstraction layer git’s (frontend) commands give you.

So in this Understanding Git series, we will cover git’s internals (we will not go into git’s source code don’t worry) and the first thing on that list is git’s heart and soul — the data model.
To start, we will initialize an empty git repository in our project directory:
git initGit will inform us it has created a .git directory in our project’s directory so let’s take a quick peek at how it looks like:
$ tree .git/.git/
├── HEAD
├── config
├── description
├── hooks
│ ├── applypatch-msg.sample
│ ├── commit-msg.sample
│ ├── post-update.sample
│ ├── pre-applypatch.sample
│ ├── pre-commit.sample
│ ├── pre-push.sample
│ ├── pre-rebase.sample
│ ├── pre-receive.sample
│ ├── prepare-commit-msg.sample
│ └── update.sample
├── info
│ └── exclude
├── objects
│ ├── info
│ └── pack
└── refs
├── heads
└── tags8 directories, 14 files
Some of these files and directories may sound familiar to you (particularly HEAD) but for now, we will focus on the .git/objects directory which is empty right now, but we will change that in a moment.
Let’s create an index.php file
touch index.phpgive it some content
<?php
echo "Hello World";and a README.md file
touch README.mdand give it some content too:
# Description
This is my hello world projectNow let’s stage and commit them:
git add .
git commit -m "Initial Commit"OK, nothing special here, adding and committing — we’ve all “been there, done that”.
If we take a look again at our .git directory we can see that the .git/objects directory has some subdirectories and files now:
├── objects
│ ├── 5d
│ │ └── 92c127156d3d86b70ae41c73973434bf4bf341
│ ├── a6
│ │ └── dbf05551541dc86b7a49212b62cfe1e9bb14f2
│ ├── cf
│ │ └── 59e02c3d2a2413e2da9e535d3c116af1077906
│ ├── f8
│ │ └── 9e64bdfcc08a8b371ee76a74775cfe096655ce
│ ├── info
│ └── pack(Note: directories and files can/will have different names on your computer)
We will get back to .git/objects but for now, notice that every directory name is two characters long. Git generates a 40-character checksum (SHA-1) hash for every object and the first two characters of that checksum are used as a directory name and the other 38 as file (object) name.
The first kind of objects that git creates when we commit some file(s) are blob objects, in our case two of them, one for each file we committed:
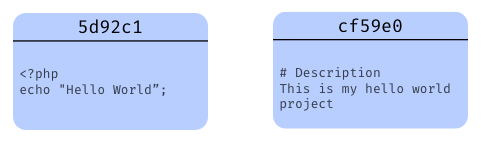
They contain snapshots of our files (the content of our files at the time of the commit) and have their checksum header.
The next kind of object git creates are tree objects. In our case there is only one and it contains a list of all files in our project with a pointer to the blob objects assigned to them (this is how git associates your files with their blob objects):
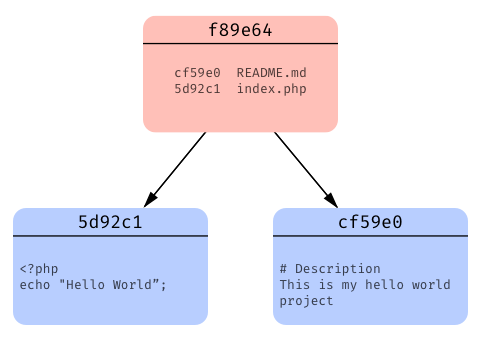
And finally git creates a commit object that has a pointer to it’s tree object (along with some other information):
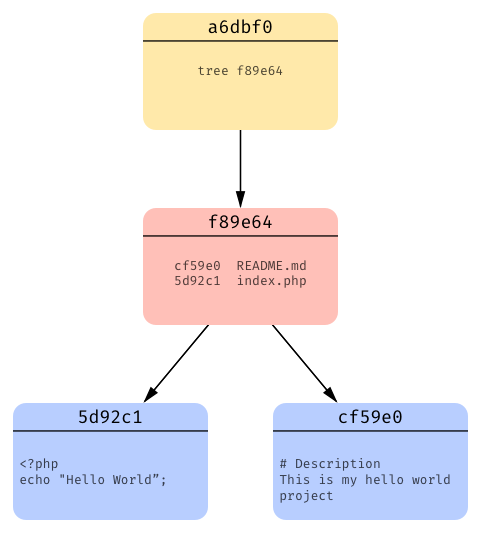
If we look back at our .git/objects directory things should look clearer now.
├── objects
│ ├── 5d
│ │ └── 92c127156d3d86b70ae41c73973434bf4bf341
│ ├── a6
│ │ └── dbf05551541dc86b7a49212b62cfe1e9bb14f2
│ ├── cf
│ │ └── 59e02c3d2a2413e2da9e535d3c116af1077906
│ ├── f8
│ │ └── 9e64bdfcc08a8b371ee76a74775cfe096655ce
│ ├── info
│ └── packWith git log we can see our commit history:
commit a6dbf05551541dc86b7a49212b62cfe1e9bb14f2
Author: zspajich <zspajich@gmail.com>
Date: Tue Jan 23 13:31:43 2018 +0100Initial Commit
And using the naming convention we mentioned earlier we can find our commit object in .git/object :
├── objects
│ ├── a6
│ │ └── dbf05551541dc86b7a49212b62cfe1e9bb14f2To look at it’s content we can’t simply use cat command since these are not plain text files but git has a cat-file command we can use:
git cat-file commit a6dbf05551541dc86b7a49212b62cfe1e9bb14f2to get the content of our commit object:
tree f89e64bdfcc08a8b371ee76a74775cfe096655ce
author zspajich <zspajich@gmail.com> 1516710703 +0100
committer zspajich <zspajich@gmail.com> 1516710703 +0100Initial Commit
Here we see the pointer to our commit’s tree object and to examine it’s content we use git ls-tree command:
git ls-tree f89e64bdfcc08a8b371ee76a74775cfe096655ceand as expected it does contain a list of our files with pointers to their blob objects:
100644 blob cf59e02c3d2a2413e2da9e535d3c116af1077906 README.md
100644 blob 5d92c127156d3d86b70ae41c73973434bf4bf341 index.phpWe can look at blob object representing (for example) index.php with cat-file command:
git cat-file blob 5d92c127156d3d86b70ae41c73973434bf4bf341and we see that it contains our index.php file’s content
<?
echo "Hello World!"So that is what happens when we create and commit some files.
Now we’ll do another commit, this time let’s say we made some changes to our index.php file (added some code magic) and commited those changes:

As we see, git has now created a new blob object with a new snapshot of index.php. Since README.md hasn’t changed, no new blob object for it is created, git will reuse the existing one instead (we’ll see in a second how).
Now, when git creates a tree object, blob pointer assigned to index.php is updated and blob pointer assigned to README.md simply stays the same as in the previous commit’s tree.
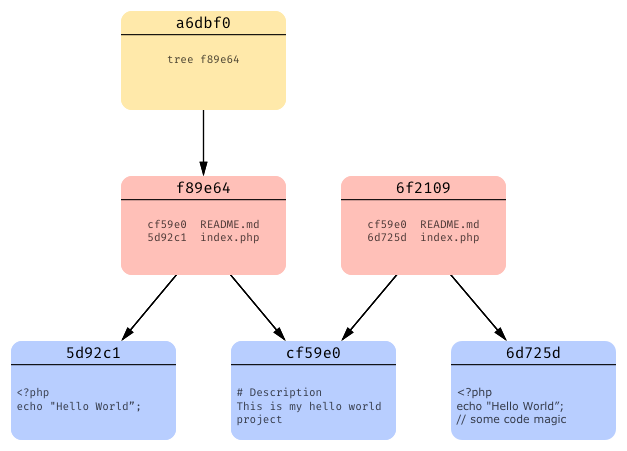
And at the end, git creates a commit object with a pointer to it’s tree object
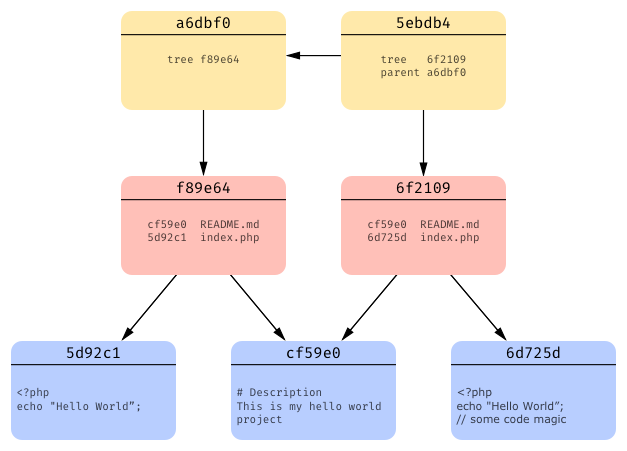
and also a pointer to it’s parent commit object (every commit except the first one has at least one parent).
So now that we know how git handles file adding and editing, the only thing that remains is to see how it handles file deletion:
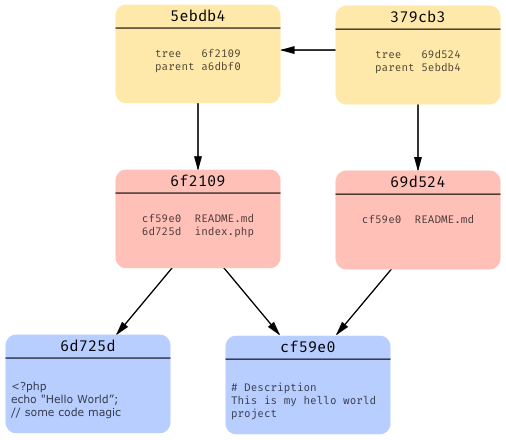
It’s very simple — git deletes the file entry (filename with a pointer to its blob object) from the tree object. In this case we deleted index.php in our commit so there is no longer an index.php entry in that commit’s tree object (in other words, our commit’s tree object no longer has a pointer to a blob object representing index.php).
There is just one more addition to this data model we presented— tree objects can be nested (they can point to other tree objects). You can think of it this way: every blob object represents a file and every tree object represents a directory, so if we have nested directories we will have nested tree objects.
Let’s look at an example:
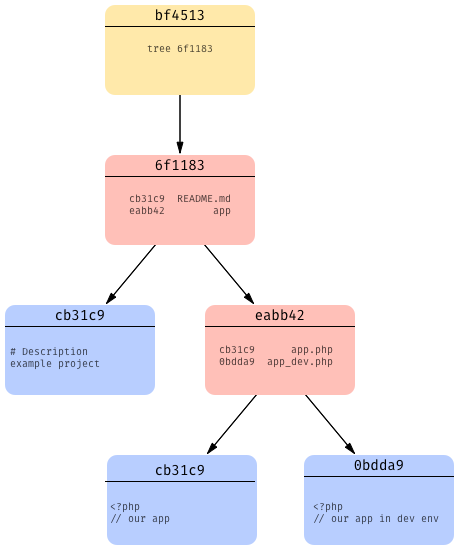
Here, our project would have one README.md file and one app directory with two files ( app.php and app_dev.php).
Git uses blob objects to recreate the content of our files at any given point in time (commit) and tree objects to reproduce our project’s folder structure.
So there you have it - git’s data model. It is, in fact, a simple data model and in next post, we’ll look at branching and how git’s data model makes branching very cheap and simple.
If you wish to dig deeper into git’s data model I would recommend this lecture from Scott Chacon and also going through Git Internals chapter from his Git Pro book.
